True or false? Scientific content in mass media
15 December 2014
Credibility on the Internet
The easy search for information and its wide accessibility is surely one of the most important achievements of today’s world. Yet, when it comes to obtaining credible information to be used in different domains of social life, the Internet is not always the best source. This problem is hardly noticeable when common information is searched for. But it becomes relatively visible when it comes to looking for unknown information or unobvious details (Fig. 1). For example, if you are searching the Internet for a picture of a celebrity, you can easily eliminate those representing other people.
However, in order to judge a properly presented DNA structure, you need to have some information beforehand (e.g. that the DNA is a right-handed double helix with a major and minor groove; Watson and Crick, 1953). Just like someone’s look-alike is not this exact person, the details of the DNA architecture should not be disregarded on a certain level of detailed view.

Fig. 1. Searching for and judging known and unknown information.
In Google image search (images.google.com), you can easily find an image of (a) Barack Obama, the current president of USA (“current president of america” was typed into the search engine) or (b) a scheme representing the spatial structure of DNA (“dna double helix” was typed into the search engine). The images representing Barack Obama or the actual structure of DNA were ticked green, the wrong ones were marked with a red x.
So where should we look for credible information that we are unable to judge in terms of its merits, as it goes beyond our knowledge? For ages it was the encyclopaedia that was the most reliable source of information, but in contemporary times it is not updated fast enough. Wikipedia seems to be the answer for the problems of the contemporary world. But is it really so?
Wikipedia as the first source of knowledge
An interesting discussion was initiated by an article published in the scientific journal Nature (Giles, 2005). In this article (which was not reviewed), the author presents the results of comparing 42 chosen entries from Encyclopædia Britannica and Wikipedia1 regarding exact sciences, which were then rated by experts in the field. It turned out that in both encyclopaedias there were 4 major errors consisting in wrong entry definition, and additionally 123 and 162 minor errors, respectively in Encyclopædia Britannica and Wikipedia. As one might expect, the Encyclopædia Britannica editorial team responded to the article published in Nature with an official letter, and the journal also did not remain indifferent to the statement of the Encyclopædia Britannica editorial team. It is beyond doubt, however, that today, when access to the Internet has become common, it is Wikipedia that is the source of information accessible to everyone. Considering Wikipedia’s credibility, physicians from Belgium and from United States attempted to identify the most visited source of information among Internet users: is it Wikipedia, or other Internet services, e.g. those maintained by the National Institute of Health?
“Genetic code” in media and in law
A good example of a notion which has its separate (false) definition in the mass media (and, unfortunately, not only) is the notion of genetic code. In many information services we can hear that “two samples demonstrated compliance with the DNA genetic code of Krzysztof Olewnik, while one had a different profile” (‘Gazeta Wyborcza’, 4.09.2013), “lead-based solders and mutagenic compounds which can easily permeate the soil (…) cause changes in genetic code” (Polskieradio.pl, 7.09.2013), or “(…) if it turns out that the donor’s genetic code is compliant with the one of the patient, the transplant can be performed. The above examples can seem distant from our everyday problems.
The editor-in-chief of Biological and Environmental Education (Edukacja Biologiczna i Środowiskowa) has the privilege to read articles that are sent to the editor’s office.
This reading surprisingly leads to another example close to our hearts.
In publications concerning health education, an article entitled ‘Introduction of a comprehensive program for health education and promotion of health in schools’ (Wprowadzenie w szkołach wszechstronnego programu edukacji zdrowotnej i promocji zdrowia), published in ‘Lider’ in 1993 is often quoted. Yet there are some discrepancies concerning the author’s identity.
Until now, I have come across the following versions of the name: Nakijma, Nakaijama, Nakaijma, Nakajim and Nakajima. Only because I speak Japanese do I know that the latter, Nakajima, sounds probable. Knowing the first letter of the name (which, luckily, remained intact by the “mutation”) and Nakajima’s interests, I learned that the author was Dr Hiroshi Nakajima (born
16.05.1928, died 26.01.2013), the Director-General of the World Health Organization in 1988–1998.
This example clearly indicates problems related to using today’s information technologies. Today, diverse kinds of information can be easily found (even multiple versions of the same information), but the final judgment of what is true often relies on the very narrow and specialist knowledge of single Internet users.Wyborcza’, 18.09.2013).
You can even learn about the oak “Bartek” that its “sprouts with genetic code collected by scientists will be used for cloning the tree and growing little seedlings” (Onet.pl, 24 June 2014).
In the case of the definition of genetic code, Wikipedia provides correct information that it is a set of rules allowing the translation of DNA and mRNA nucleotide sequence into an order of amino acids in the process of translation. Thus, one can deduce that translation is a process involving genetic code for changing the nucleotide language into an amino acid script of the same information.
It is worth noticing that genetic code was discovered in 1960s (Gardner et al., 1962, Wahba et al., 1963) and it is universal. It means it is identical in all living organisms on Earth which, by the way, allowed genetic engineering to blossom. The transfer of genes between organisms would be difficult to imagine if each of them had a different genetic code. Not mentioning the fact that, according to the correct definition of genetic code, the phrase “compliance of the genetic code between two people” sounds absurd. Since it is obvious that every human has the same genetic code, which was broken in 1960s, and which differs only slightly in the nucleotide sequence of DNA influencing the set of proteins, which results in individual differences. Therefore, the following provisions in the Personal Data Protection Act of 29 August 1997 sound very dangerous (uniform text: Polish Journal of Laws of 2002, no. 101, item 926):
Article 27.1.
It is forbidden to process data that disclose race or ethnic background, (…) data concerning medical conditions, genetic code, addictions or sexual life (…).
Article 49.2.
If the offence concerns data that disclose race or ethnic background, (…) data concerning medical conditions, genetic code, addictions or sexual life, the offender shall be subject to a fine, restriction of liberty or imprisonment up to 3 years. In this case, we can only count on amendments to the law, thanks to which revealing the genetic code (Fig.2) will not be punished with restriction of freedom or imprisonment.
Perhaps the correct definition of genetic code, widely accessible thanks to Wikipedia, will contribute to changes in the lawmakers’ consciousness?
This is apparently the case when Wikipedia – the most widely used source of information on the Internet – has not been taken seriously by lawmakers.
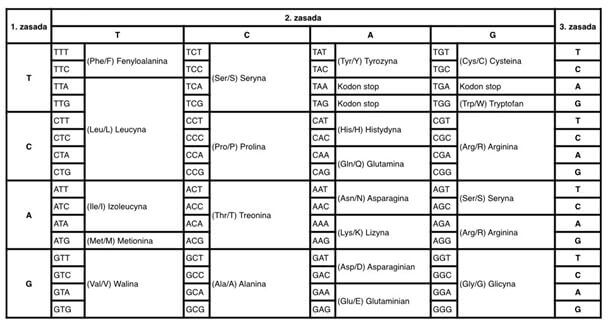
Fig. 2. A criminal offence, or revealing of the genetic code.Conclusion Sources
An example close to our hearts
The above examples can seem distant from our everyday problems. The editor-in-chief of Biological and Environmental Education (Edukacja Biologiczna i Środowiskowa) has the privilege to read articles that are sent to the editor’s office. This reading surprisingly leads to another example close to our hearts. In publications concerning health education, an article entitled ‘Introduction of a comprehensive program for health education and promotion of health in schools’ (Wprowadzenie w szkołach wszechstronnego programu edukacji zdrowotnej i promocji zdrowia), published in ‘Lider’ in 1993 is often quoted. Yet there are some discrepancies concerning the author’s identity.
Until now, I have come across the following versions of the name: Nakijma, Nakaijama, Nakaijma, Nakajim and Nakajima. Only because I speak Japanese do I know that the latter, Nakajima, sounds probable. Knowing the first letter of the name (which, luckily, remained intact by the “mutation”) and Nakajima’s interests, I learned that the author was Dr Hiroshi Nakajima (born 16.05.1928, died 26.01.2013), the Director-General of the World Health Organization in 1988–1998. This example clearly indicates problems related to using today’s information technologies.
Today, diverse kinds of information can be easily found (even multiple versions of the same information), but the final judgment of what is true often relies on the very narrow and specialist knowledge of single Internet users.
Conclusion
The above described errors can be found in the Internet, as well as in the mass media, which – exactly because of their mass range – shape the consciousness of the recipients of the information.
Thus, they teach the recipients, ensuring them at the same time that the erroneous notions are in fact the correct ones. The authors of the Personal Data Protection Act must have held a strong belief that their understanding of the notion “genetic code” was true, as they obviously have not even bothered to check its correct meaning.
Yet such errors are being diffused and perpetuated not only through the media and not only in the verbal layer.
Due to unlimited use of schemes within the Internet, among others by computer graphic designers, erroneous visual information can be found even in publications where merits-related correctness should be especially taken care of (Fig. 3).
This phenomenon becomes an increasingly serious issue due to the massive licencing of graphical works by banks of computer graphics (e.g. Fotolia, Shutterstock, iStockphoto).
For this reason it has become extremely important to be aware of the use of such internet resources that refer to scientific knowledge.
The example of the DNA structure indicates the need to control, in almost every single case, the merits-related correctness of the picture and if it is not misleading for the recipients.
It is not inconceivable that further engagement of the scientific community in diverse activities concerning popularisation of knowledge through the Internet will have positive results in eliminating commonly reproduced errors, and will contribute to greater social consciousness in terms of what is true and what is false.

Fig. 3. DNA structure in an advertisement and on a book cover
Incorrect DNA structure can incidentally be seen (a) in an ad at a bus stop or (b) on the cover of a biology book. To determine what is correct and what is not, in that case, one can use not only the Internet but also a quite common dextrorotary structure – a corkscrew.
1. This article, as well as the studies cited, refer only to the English version of Wikipedia.
Acknowledgements
The author would like to thank Dr Marcin Trepczyński for devoting his time to correcting this text, giving it his final touches, and thus making it more legible.
Author: Takao Ishikawa
Source:
Callis KL, Christ LR, Resasco J, Armitage DW, Ash JD, Caughlin TT, Clemmensen SF, Copeland SM, Fullman TJ, Lynch RL, Olson C, Pruner RA, Vieira-Neto EH, West-Singh R, Bruna EM (2009).
Improving Wikipedia: Educational opportunity and professional responsibility. Trends Ecol Evol, 24:177e9.
Daub J, Gardner PP, Tate J, Ramsköld D, Manske M, Scott WG, Weinberg Z, Griffiths-Jones S, Bateman A (2008). The RNA WikiProject: Community annotation of RNA families.RNA, 14:2462-2464.
Gardner RS, Wahba AJ, Basilio C, Miller RS, Lengyel P, Speyer JF (1962).
Synthetic polynucleotides and the amino acid code.VII.Proc Natl Acad Sci USA, 48:2087-2094.Giles J (2005).Internet encyclopaedias go head to head.Nature, 438:900-901.
Hodis E, Prilusky J, Martz E, Silman I, Moult J, Sussman JL (2008).
Proteopedia – A scientific “wiki” bridging the rift between 3D structure and function of biomacromolecules. Genome Biol, 9:R121.
Huss JW 3rd, Orozco C, Goodale J, Wu C, Batalov S, Vickers TJ, Valafar F, Su AI (2008).
A gene wiki for community annotation of gene function. PLoS Biol, 6:e175.
Laurent MR, Vickers TJ (2009). Seeking health information online: Does Wikipedia matter?
J Am Med Inform Assoc, 16:471-479.
Leithner A, Maurer-Ertl W, Glehr M, Friesenbichler J, Leithner K, Windhager R (2010).
Wikipedia and osteosarcoma: A trustworthy patients’ Kinformation? J Am Med Inform Assoc, 17:373-374.
Mons B, Ashburner M, Chichester C, van Mulligen E, Weeber M, den Dunnen J, van Ommen GJ, Musen M, Cockerill M, Hermjakob H, Mons A, Packer A, Pacheco R, Lewis S, Berkeley A, Melton W, Barris N, Wales J, Meijssen G, Moeller E, Roes PJ, Borner K, Bairoch A. (2008).
Calling on a million minds for community annotation in WikiProteins.
Genome Biol, 9:R89.
Wahba AJ, Gardner RS, Basilio C, Miller RS, Speyer JF, Lengyel P (1963) Synthetic polynucleotides and the amino acid code.VIII.Proc Natl Acad Sci USA, 49:116-122.Watson JD, Crick FH (1953).Molecular structure of nucleic acids; a structure for deoxyribose nucleic acid.
Nature, 171:737-738.
Summary: Contemporary societies have access to a great amount of more or less detailed information.
The Internet is a good example: you can find information on elementary particles and gossip about celebrities’ lives just as easily. What is becoming more and more crucial in present times is not the ability to distinguish between more and less important information but, perhaps above all, the ability to identify the real and reject the false.
Keywords: media, means of communication, Internet, information, scientific content















