Prawda czy fałsz? Treści naukowe w środkach masowego przekazu
15 grudnia 2014
Współczesne społeczeństwa mają dostęp do ogromnej ilości informacji o zróżnicowanym stopniu szczegółowości. Internet jest tego dobrym przykładem – z niemal taką samą łatwością można znaleźć informacje o cząstkach elementarnych, co plotki z życia celebrytów. W obecnych czasach coraz ważniejsza staje się zdolność odróżniania nie tylko ważnych i mniej ważnych informacji, ale być może przede wszystkim umiejętność zdobywania prawdziwych informacji i odrzucania fałszywych.
Wiarygodność w internecie
Łatwość wyszukiwania informacji i szeroka ich dostępność jest z pewnością jedną z ważniejszych zdobyczy współczesnego świata. Jednak gdy chodzi o dotarcie do wiarygodnych informacji, które mają być wykorzystane w rozmaitych dziedzinach życia społecznego, internet nie zawsze stanowi najlepsze źródło. Problem ten jest niemal niezauważalny, jeśli przedmiotem poszukiwań są znane informacje. Staje się on zaś stosunkowo łatwo dostrzegalny, gdy szuka się nieznanych informacji lub nieoczywistych szczegółów (ryc. 1). Na przykład w trakcie szukania w internecie wizerunku znanej osoby od razu można odrzucić zdjęcia przedstawiające inną postać. Jednak aby ocenić prawidłowo przedstawioną strukturę DNA, trzeba mieć pewien zasób informacji (m.in. o tym, że DNA jest prawoskrętną podwójną helisą z tzw. grubym i wąskim rowkiem; Watson i Crick, 1953). Podobnie jak sobowtór znanej osoby nie jest jednak tą osobą, szczegóły budowy DNAna pewnym etapie szczegółowości nie są i nie powinny pozostawać obojętne.

Ryc. 1. Wyszukiwanie i ocena informacji znanych i nieznanych.
W wyszukiwarce obrazów Google (images.google.com) można łatwo znaleźć wizerunek (a) Baracka Obamy, obecnego Prezydenta USA (wpisano do wyszukiwarki “aktualny prezydent ameryki”) lub (b) schemat przedstawiający strukturę przestrzenną DNA (wpisano do wyszukiwarki “dna double helix”, pol. podwójna helisa DNA).Rysunki przedstawiające Baracka Obamę lub prawidłową strukturę DNA oznaczono zieloną fajką, zaś błędne oznaczono czerwonym iksem.
W takim razie gdzie szukać wiarygodnych informacji, których nie sposób ocenić pod względem merytorycznym, ponieważ wykraczają poza zasób wiedzy osoby szukającej? Od wieków za pewne źródło informacji była uznawana encyklopedia, jednak w obecnych czasach nie zawsze jest ona wystarczająco szybko aktualizowana. Wydaje się, że Wikipedia jest odpowiedzią na problemy współczesnego świata. Ale czy na pewno?
Wikipedia jako pierwsze źródło wiedzy
Ciekawą dyskusję rozpoczął artykuł opublikowany w renomowanym czasopiśmie naukowym Nature (Giles, 2005). W artykule (który nie został poddany recenzjom) autor przedstawił wyniki porównań 42 wybranych haseł z Encyclopædia Britannica i Wikipedii1 z zakresu nauk ścisłych, które zostały poddane ocenie ekspertów z danej dziedziny. Okazało się, że w obu encyklopediach znalazły się 4 poważne błędy polegające na podaniu błędnej definicji hasła, a także 123 i 162 mniejsze błędy, odpowiednio, w Encyclopædia Britannica i Wikipedii. Jak można było się spodziewać, zespół redakcyjny Encyclopædia Britannica zareagował oficjalnym listem na artykuł opublikowany w Nature, zaś tygodnik naukowy również nie pozostawał obojętny wobec stanowiska zespołu redakcyjnego Encyclopædia Britannica. Nie ulega jednak wątpliwości, że w obecnych czasach, w których dostęp do internetu stał się powszechny, Wikipedia jest źródłem informacji dostępnym dla każdego. Zastanawiając się nad wiarygodnością Wikipedii, lekarze z Belgii i Stanów Zjednoczonych sprawdzili, jakie źródło informacji jest najczęściej odwiedzane przez użytkowników internetu – czy Wikipedia, czy inne serwisy internetowe, np. utrzymywane przez Narodowy Instytut Zdrowia Stanów Zjednoczonych (National Institute of Health).
Autorom tego badania udało się wykazać, że Wikipedia jest częściej odwiedzana niż wiele innych źródeł informacji (Laurent i Vickers, 2009). Tym bardziej zasadne jest więc pytanie o wiarygodność informacji znajdujących się w Wikipedii, szczególnie w obszarze ochrony zdrowia, który istotnie może wpływać na życie i zdrowie osób szukających takich informacji. Z tego też powodu temat ten został podjęty przez wiele zespołów uczonych i lekarzy. Wiele do tej pory przeprowadzonych badań wskazuje na to, że Wikipedia jest często wykorzystywanym źródłem informacji o rozmaitych chorobach (Laurent i Vickers, 2009), ale dokładniejsze badania porównujące treść Wikipedii i innych źródeł, np. utrzymywanych przez amerykański NIH, wykazały, że pod względem rzetelności korzystniej wypadają źródła będące pod stałym nadzorem agencji rządowych. Tego rodzaju badania porównawcze zostały wykonane przez lekarzy specjalizujących się w kostniakomięsakach (łac. osteosarcoma), którzy porównali treść Wikipedii dotyczącą kostniakomięsaków z informacjami podanymi na stronach internetowych Narodowego Instytutu Nowotworów (National Cancer Institute), będącego częścią NIH, a także z treścią podaną w recenzowanych przez specjalistów książkach (Leithner i wsp., 2010). Wyniki badań wskazują na to, że Wikipedia jest pierwszym wyborem dla osób niezwiązanych z medycyną, m.in. z powodu prostego języka, ale informacje dostępne w Wikipedii częściej ulegają dezaktualizacji, co istotnie może wpływać na poziom wiedzy pacjentów oraz osób szukających informacji o kostniakomięsakach. Autorzy wyżej wspomnianej pracy sugerują, by osoby piszące artykuły do Wikipedii częściej zamieszczały odnośniki (tzw. linki) do odpowiednich stron agencji rządowych, takich jak NIH (Leithner i wsp., 2010). Inne postulaty, uzupełniające się z sugestiami autorów wyżej wymienionej pracy, były formułowane już wcześniej: redagowanie artykułów Wikipedii jako element zajęć dydaktycznych na uczelniach wyższych i zaangażowanie naukowców do redagowania tekstów zamieszczanych w internetowej encyklopedii (Callis i wsp., 2009). Takie zajęcia dydaktyczne realizowane są na Uniwersytecie Warszawskim w ramach przedmiotu „English for academic purposes”, zresztą podobny pomysł został już wcześniej zrealizowany przez społeczność naukowców zajmujących się badaniami nad RNA (Daub i wsp., 2008), białkami (Hodis i wsp., 2008; Mons i wsp., 2008) i funkcjami genów (Huss i wsp., 2008). Warto więc zwrócić uwagę, że część uczonych, dostrzegając powszechną popularność Wikipedii, wzięła sprawy we własne ręce i podjęła się redagowania artykułów Wikipedii. Wydaje się, że współpraca miłośników poszczególnych dziedzin nauki (często umieszczający artykuły, wymagające jednak pewnych uzupełnień) i naukowców (mających rzetelną wiedzę z określonej dziedziny i dostęp do najnowszych osiągnięć naukowych) może być wyjątkowo owocna i pożyteczna dla całego społeczeństwa.
„Kod genetyczny” w mediach i w prawie
Bardzo dobrym przykładem tego, co ma osobną (fałszywą) definicję w środkach masowego przekazu (i niestety nie tylko), jest pojęcie kodu genetycznego. W wielu serwisach informacyjnych możemy przeczytać, że „dwie próbki wykazały zgodność DNA z kodem genetycznym Krzysztofa Olewnika, natomiast jedna wykazała inny od pozostałych profil” (Gazeta Wyborcza, 4.09.2013 r.), „stopy lutownicze na bazie ołowiu i związki mutagenne, które mogą łatwo przenikać do gleby (…) powodują zmiany w kodzie genetycznym” (Polskieradio.pl, 7.09.2013 r.) albo „(…) jeśli okaże się, że kod genetyczny dawcy zgadza się z kodem genetycznym chorego, wtedy dochodzi do przeszczepienia” (Gazeta Wyborcza, 18.09.2013 r.). O dębie Bartku można się nawet dowiedzieć, że „pobrane przez naukowców pędy z kodem genetycznym posłużą do sklonowania drzewa w celu powstania małych sadzonek” (Onet.pl, 24 czerwca 2014 r.). W przypadku definicji kodu genetycznego, Wikipedia zawiera całkowicie prawdziwą informację, która mówi o tym, że jest to zbiór reguł pozwalających przetłumaczyć sekwencję nukleotydową DNA i mRNA na kolejność aminokwasów w procesie translacji. Można więc stwierdzić, że translacja (tłumaczenie) to proces wykorzystujący kod genetyczny do zmiany języka nukleotydów na zapis aminokwasowy tych samych informacji. Warto zwrócić uwagę, że kod genetyczny został poznany już w latach 60. ubiegłego stulecia (Gardner i wsp., 1962; Wahba i wsp., 1963) i jest on uniwersalny. Oznacza to, że jest on tożsamy u wszystkich organizmów żyjących na Ziemi, co zresztą przyczyniło się do rozkwitu inżynierii genetycznej. Trudno sobie wyobrazić bowiem przenoszenie genów między organizmami, gdyby każdy z nich miał inny kod genetyczny, nie wspominając o tym, że w świetle prawidłowej definicji kodu genetycznego zupełnie absurdalnie brzmi sformułowanie „zgodność kodu genetycznego między dwojgiem ludzi”. Jest przecież oczywiste, że każdy człowiek ma taki sam kod genetyczny rozszyfrowany w latach 60. XX wieku, a w niewielkim stopniu różni się jedynie pod względem sekwencji nukleotydowej DNA, która wpływa na nieco inny zestaw białek przekładający się na różnice osobnicze.
Wobec tego naprawdę groźnie brzmią przepisy ustawy z dnia 29 sierpnia 1997 r. o ochronie danych osobowych (tekst jedn.: Dz. U. 2002 r. Nr 101, poz. 926):
Art. 27. 1. Zabrania się przetwarzania danych ujawniających pochodzenie rasowe lub etniczne, (…) danych o stanie zdrowia, kodzie genetycznym, nałogach lub życiu seksualnym (…).
Art. 49. 2. Jeżeli czyn (…) dotyczy danych ujawniających pochodzenie rasowe lub etniczne, (…) danych o stanie zdrowia, kodzie genetycznym, nałogach lub życiu seksualnym, sprawca podlega grzywnie, karze ograniczenia wolności albo pozbawienia wolności do lat 3.
W tym przypadku należy jedynie liczyć na zmianę zapisu prawa, dzięki której ujawnianie kodu genetycznego (ryc. 2) nie będzie zagrożone karą ograniczenia wolności albo pozbawienia wolności. Być może prawidłowa definicja kodu genetycznego szeroko dostępna dzięki Wikipedii przyczyni się do zmiany świadomości osób stanowiących prawo? Jest to najwyraźniej przypadek, w którym Wikipedia – najczęściej wykorzystywane źródło informacji w internecie – nie została potraktowana poważnie przez ustawodawcę.
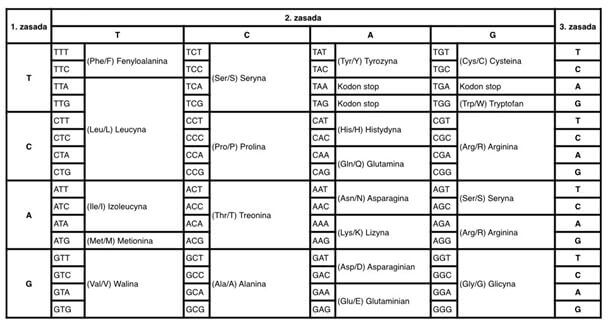
Ryc. 2. Czyn zagrożony karą, czyli ujawnienie kodu genetycznego.
Bliski nam przykład
Wyżej opisane przykłady mogą się wydawać się odległe od naszych codziennych problemów. Przywilejem redaktora naczelnego Edukacji Biologicznej i Środowiskowej jest czytanie artykułów przysyłanych do redakcji. Lektura ta nieoczekiwanie prowadzi do kolejnego, bliskiego nam wszystkim przykładu. W artykułach dotyczących edukacji zdrowotnej często cytowana jest praca Wprowadzenie w szkołach wszechstronnego programu edukacji zdrowotnej i promocji zdrowia, opublikowana w 1993 r. Ale co do autora tej pracy, opublikowanej w czasopismie Lider, nie ma zgodności. Do tej pory spotkałem się z następującymi nazwiskami autora: Nakijma, Nakaijama, Nakaijma, Nakajim albo wreszcie Nakajima. Wyłącznie dlatego, że znam język Japoński, wiem, że ostatnie nazwisko, Nakajima, brzmi prawdopodobnie. Znając pierwszą literę imienia (która szczęśliwie nie uległa „mutacji”) i zainteresowania Nakajimy, dowiedziałem się, że autorem tego tekstu jest dr Hiroshi Nakajima (ur. 16.05.1928, zm. 26.01.2013), szef Światowej Organizacji Zdrowia w latach 1988–1998. Przykład ten wyraźnie wskazuje na problemy związane z korzystaniem z dzisiejszych technologii informacyjnych. Obecnie z łatwiością można znaleźć rozmaite informacje (nawet wiele wersji tej samej informacji), ale ostateczna ocena tego, co jest prawdziwe, opiera się na wiedzy, często bardzo wąskiej i specjalistycznej, każdego użytkownika internetu.
Wnioski
Wyżej opisane błędy można spotkać zarówno w internecie, jak i w środkach masowego przekazu, które – właśnie dzięki umasowieniu – kształtują świadomość odbiorców informacji. Tym samym uczą odbiorców, a zarazem utwierdzają ich w przekonaniu, że błędne pojęcia w rzeczywistości są prawidłowe. Autorzy ustawy o ochronie danych osobowych musieli być silnie przekonani, że poprawnie rozumieją termin „kod genetyczny”, skoro najwyraźniej nie podjęli się sprawdzenia właściwego znaczenia.
Jednak nie tylko w mediach i nie tylko w warstwie słownej błędy takie bywają rozpowszechniane i utrwalane. Z powodu dowolnego wykorzystywania schematów za pośrednictwem internetu, m.in. przez grafików komputerowych, błędne informacje obrazowe można spotkać nawet w publikacjach, w których szczególnie powinno się dbać o poprawność merytoryczną (ryc. 3). Zjawisko to staje się coraz poważniejsze ze względu na masowe udzielanie licencji do utworów graficznych przez banki grafiki komputerowej (jak np. Fotolia, Shutterstock, iStockphoto). Z tego powodu szczególnie ważne staje się świadome korzystanie z takich zasobów internetu, które odwołują się do wiedzy naukowej. Przykład schematu DNA wyraźnie wskazuje na to, że niemal w każdym przypadku należy dokładnie sprawdzić, czy obraz jest poprawny merytorycznie i nie wprowadza odbiorców w błąd. Nie jest wykluczone, że jeszcze większe zaangażowanie środowiska naukowego w rozmaite aktywności upowszechniania wiedzy przez internet będzie miało pozytywne skutki w wyeliminowaniu często powielanych błędów i przyczyni się do większej świadomości społecznej o tym, co jest prawdą, a co fałszem.

Ryc. 3. Struktura DNA w reklamie i na okładce podręcznika
Nieprawidłową strukturę DNA można (a) przypadkiem zobaczyć na przystanku autobusowym na reklamie lub (b) na okładce podręcznika do biologii. W tym przykładzie, do rozstrzygnięcia, co jest prawidłowe, a co nie, może okazać się pomocny nie tylko internet, ale także stosunkowo często spotykana struktura prawoskrętna, czyli korkociąg.
1 W niniejszym artykule, a także cytowanych badanich, brano pod uwagę wyłącznie angielską wersję Wikipedii.
Autor: Takao Ishikawa
Podziękowania
Autor składa podziękowania dr. Marcinowi Trepczyńskiemu za pochylenie się nad tekstem i wprowadzenie poprawek, dzięki którym zyskał on ostateczną, bardziej czytelną formę.
Słowa kluczowe: media, środki przekazu, internet, informacja, treści naukowe
Literatura
Callis KL, Christ LR, Resasco J, Armitage DW, Ash JD, Caughlin TT, Clemmensen SF, Copeland SM, Fullman TJ, Lynch RL, Olson C, Pruner RA, Vieira-Neto EH, West-Singh R, Bruna EM (2009). Improving Wikipedia: Educational opportunity and professional
responsibility. Trends Ecol Evol, 24:177e9.
Daub J, Gardner PP, Tate J, Ramsköld D, Manske M, Scott WG, Weinberg Z, Griffiths-Jones S, Bateman A (2008). The RNA WikiProject: Community annotation of RNA families. RNA, 14:2462-2464.
Gardner RS, Wahba AJ, Basilio C, Miller RS, Lengyel P, Speyer JF (1962). Synthetic polynucleotides and the amino acid code. VII. Proc Natl Acad Sci USA, 48:2087-2094.
Giles J (2005). Internet encyclopaedias go head to head. Nature, 438:900-901.
Hodis E, Prilusky J, Martz E, Silman I, Moult J, Sussman JL (2008).
Proteopedia – A scientific “wiki” bridging the rift between 3D structure and function of biomacromolecules. Genome Biol, 9:R121.
Huss JW 3rd, Orozco C, Goodale J, Wu C, Batalov S, Vickers TJ, Valafar F, Su AI (2008). A gene wiki for community annotation of gene function. PLoS Biol, 6:e175.
Laurent MR, Vickers TJ (2009). Seeking health information online:
Does Wikipedia matter? J Am Med Inform Assoc, 16:471-479.
Leithner A, Maurer-Ertl W, Glehr M, Friesenbichler J, Leithner K, Windhager R (2010).
Wikipedia and osteosarcoma: A trustworthy patients’Kinformation? J Am Med Inform Assoc, 17:373-374.
Mons B, Ashburner M, Chichester C, van Mulligen E, Weeber M, den Dunnen J, van Ommen GJ, Musen M, Cockerill M, Hermjakob H, Mons A, Packer A, Pacheco R, Lewis S, Berkeley A, Melton W, Barris N, Wales J, Meijssen G, Moeller E, Roes PJ, Borner K, Bairoch A. (2008). Calling on a million minds for community annotation in WikiProteins. Genome Biol, 9:R89.
Wahba AJ, Gardner RS, Basilio C, Miller RS, Speyer JF, Lengyel P (1963) Synthetic polynucleotides and the amino acid code. VIII.
Proc Natl Acad Sci USA, 49:116-122.
Watson JD, Crick FH (1953). Molecular structure of nucleic acids; a structure for deoxyribose nucleic acid. Nature, 171:737-738.
True or false? Scientific content in mass media Takao Ishikawa
Contemporary societies have opportunity to gather information at different degree of complexity. Internet is the best example of this phenomenon – one can find details of elementary particles, as easy as celebrity gossip. Today, a proficiency in distingushing important information from trivial one, or rather truth from fiction, is more and more essential.
Key words: mass media, internet, information, scientific content















